Chapter 6 Data Processing
You can skip this chapter if you:
-
Can download, open, edit and save an R Markdown file
-
Can describe the advantages of repeatable workflows
-
Can execute code in an R Markdown file
6.1 Workflows
Throughout this book, I have been talking about the importance of repeatable workflows.
If you’re on a course that I’m teaching, I will share R Markdown documents with you that you can edit and I can view. We could both start with the same dataset, and by sharing our workflow, we can both know exactly what the other person has done. This data transparency is very important. Knowing what changes have been made to the data, and how those changes were made, can help prevent small mistakes being magnified. For example, a simple copy/paste error in excel, resulted in an Edinburgh hospital being delivered over two years late.
You might think this can’t apply to you, but think how many times you might make a change to a dataset in the process of cleaning that data and tidying it. If you had to describe what you did to a collaborator, would you remember every change?
One of the great advantages of using code to process data is that every stage can be documented. In this textbook I’m teaching you R, and on my courses I mainly use R Markdown files to document workflows, but R is just one statistical language and R Markdowns are just one file type. The process is the important part.
6.1.1 An example of sharing code
Imagine you have a big dataset like the UK Farm Accounts dataset:
## # A tibble: 6 × 6
## Year `Gross output at basic prices £ million` Intermediate consumption £ millio…¹ Total Income from Fa…² Agriculture's share …³ Country
## <dbl> <dbl> <dbl> <dbl> <dbl> <chr>
## 1 1995 14741. 7491. 3669. NA England
## 2 1996 14954. 7900. 3436. NA England
## 3 1997 13334. 7472. 2028. NA England
## 4 1998 12329. 7008. 1473. NA England
## 5 1999 11926. 6876. 1535. NA England
## 6 2000 10963. 6483. 941. 1.32 England
## # ℹ abbreviated names: ¹`Intermediate consumption £ million`, ²`Total Income from Farming £ million`,
## # ³`Agriculture's share of total regional employment %`And let’s say you want to explore the gross output of farming per year. You might decided it would be easier to change the name of the gross output variable to make coding easier. So you write the following in the console:
And then you summarise gross output by year:
## # A tibble: 25 × 2
## Year mean_gross_output
## <dbl> <dbl>
## 1 1995 4944.
## 2 1996 5010.
## 3 1997 4474.
## 4 1998 4115.
## 5 1999 3988.
## 6 2000 3744.
## 7 2001 3818.
## 8 2002 3876.
## 9 2003 4033.
## 10 2004 4198.
## # ℹ 15 more rowsIf you sent the above code chunk to me along with the original dataset, I would not be able to run it. I wouldn’t know what variable you had renamed. So at the start of the R Markdown document you would would want to load in the data and run any transformations/changes. That way if you sent me the RMD and the data file, I would be able to replicate what you did exactly.
As a general practice, I aim to follow this structure in my RMD or R script files:
- Load any libraries that are needed
- Load the data
- Perform any data transformations
- Perform any analyses.
There may be times when there’s a good reason to do things in a different order, but you will rarely go wrong with this order (Figure 6.1)
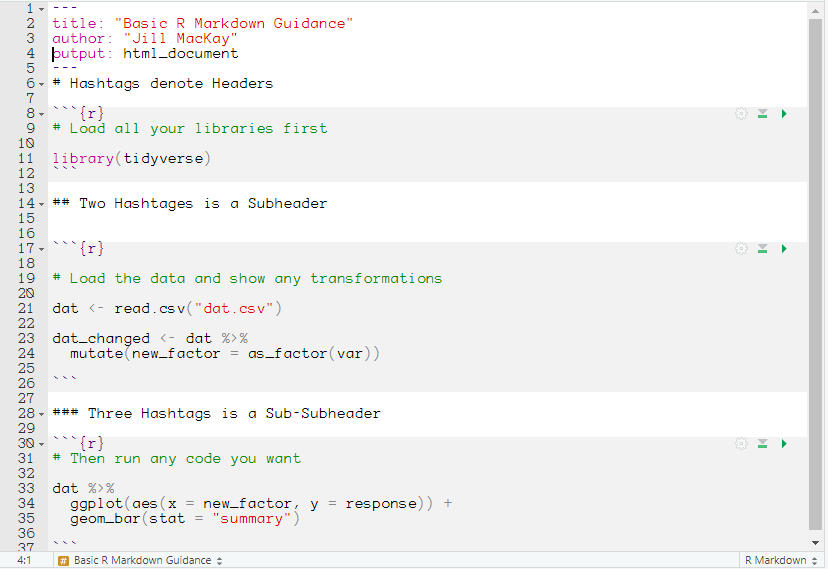
Figure: 6.1: A general format of R Markdown files
Sometimes in this book I have suggested using an R Script file instead of an R Markdown file. R Script files are good for short pieces of code, but if you want to talk about your code (say because you’re trying to ask your lecturer a question) you might find the ability to type in full paragraphs useful, and that’s where R Studio comes in. Some scientists will even write full papers in R Markdown, especially if there’s a lot of analyses in them. You can find out more about R Markdown formatting here.
6.2 Opening R Markdown Docs
R Markdown files work just like any other file in R Studio. You can open any R Markdown file by going to File > Open File ... and navigating to the folder your file is stored in.
Your R Markdown file will ‘look’ for any linked files in the same folder its saved in, so if your data is saved in the same folder your R Markdown file is saved in, you can be quite lazy about your directories, e.g. read.csv("data.csv"). This can be very helpful in repeatable analyses.
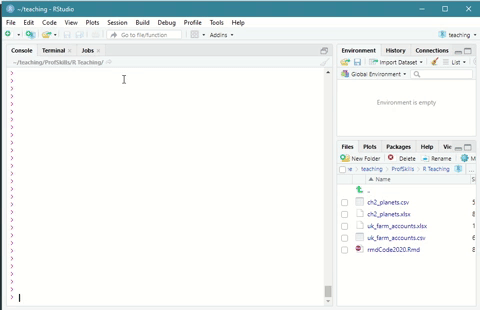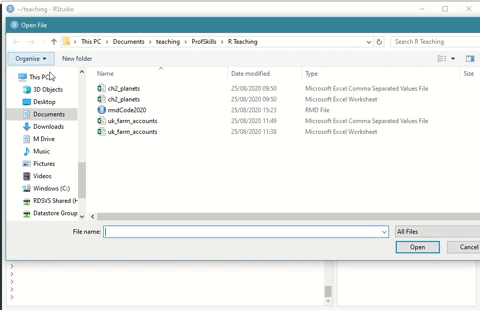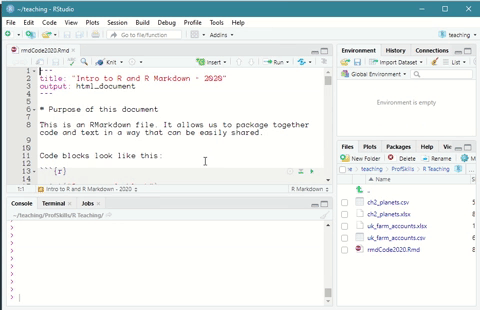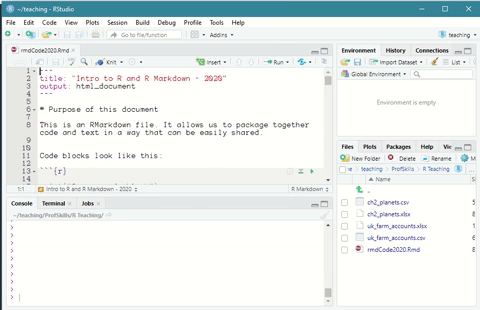
Figure: 6.2: Opening an R Markdown file in R Studio
6.3 Running Code
You can run code in R Markdown files by pressing the green ‘triangle’ button to run that specific piece of code.
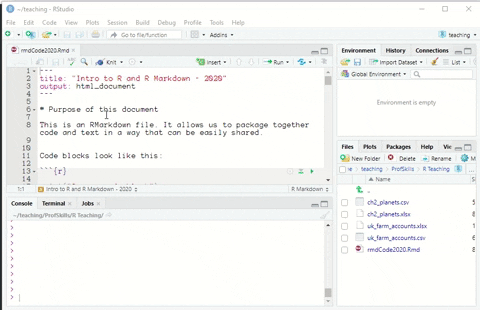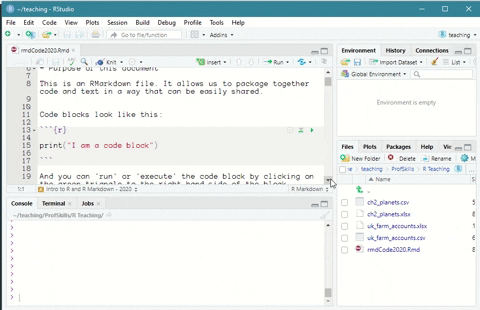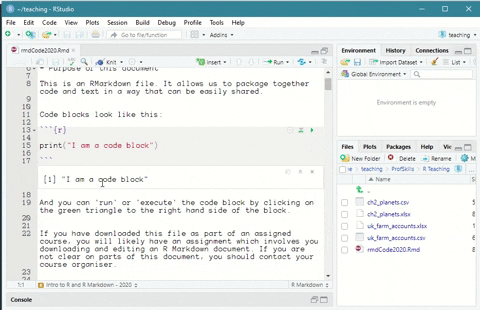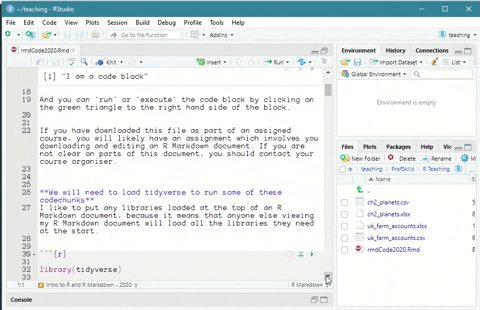
Figure: 6.3: Running a code chunk in an R Markdown file in R Studio
If you have your cursor clicked inside a code chunk you can also press ‘ctrl + enter’ on your keyboard to run that specific line.